

Herramientas a utilizar para detectar contenido duplicado
A continuación te listo los articulos donde puedes encontrar herramientas para realizar este trabajo.
Índice de contenido
Contenido del artículo
El contenido duplicado es uno de los factores SEO que más discusiones ha generado para decidir si afecta en gran medida o no al posicionamiento de una web. Pues bien, desde mi punto de vista, este es un factor importantísimo a la hora de hacer un análisis SEO o diseñar nuestra web, a pesar de que hace tiempo Google insistió en que el contenido duplicado no afectaba el ranking al menos que fuera contenido SPAM o contenido con abuso de palabras clave.
También te podría interesar: ¿cómo saber si mi web está penalizada por Google?
Como hemos podido ver leyendo el artículo sobre cómo funcionan los buscadores como Google, cuando estos indexan las páginas de una web y las registran en sus bases de datos, estos asignan un peso o nota a cada página en base a todos los factores que estamos viendo en el tutorial de análisis SEO y a los enlaces externos recibidos. Pues bien, si Google o cualquier otro buscador detecta que tenemos contenido duplicado, la nota de esa página pasará a ser penalizada en gran medida.
Hasta el 2016, si Google detectaba contenido duplicado, seguía indexando la página, aunque la posicionaba por debajo de aquellas página o páginas de las que se había copiado. Pues bien, a finales de 2016 y ya en 2017, las últimas páginas de clientes que hemos detectado que tenían contenido duplicado, Google las había eliminado del índice cuando se buscaban por palabras relacionadas con el contenido que se había duplicado. Por esta razón, claramente podemos ver que el contenido duplicado si afecta al posicionamiento.
Antes de proseguir, debemos diferenciar dos tipos de contenido duplicado:
- Interno: Contenido duplicado dentro de la propia web. Por ejemplo, una web que tiene un texto idéntico en dos páginas diferentes.
- Externo: Una de las páginas de nuestra web tiene un texto completo o fragmentos copiados de páginas externas.
De estos dos tipos de contenido duplicado, debemos destacar que el más perjudicial es el contenido duplicado externo. El contenido interno duplicado no es tan relevante pues Google omitirá este contenido en las páginas a la hora de ser analizadas. El problema que tendrá Google es el de cómo saber qué página mostrar en el buscador cuando un usuario busca por el contenido interno duplicado. Por esta razón, debemos asegurarnos que no hay contenido duplicado en los textos de nuestras páginas principales y que pertenecen a nuestra arquitectura SEO y que el contenido duplicado interno es el menor posible en nuestra web.
¿Cómo sabe google cual es el contenido original y cual el duplicado?
La respuesta es muy sencilla. Google indexa páginas y la primera página que indexa es la página original siendo copias toda página que indexe posteriormente. Es una pena, pues a veces podemos crear un contenido muy bueno y alguien nos lo copia, pero puede pasar que Google primero descubra el contenido copiado, pasando a ser nuestro contenido el contenido duplicado.
Recomendación: Envía a Google tu contenido nada más ser publicado.
¿Cómo saber si tengo contenido duplicado?
Detectar contenido duplicado Interno
Para detectar contenido interno hay diferentes herramientas. Una de nuestras favoritas es Raven Tools, pero hay otras herramientas especializadas y que son gratuitas. Como comentábamos anteriormente, el contenido duplicado no va a afectar a nuestro posicionamiento al menos que haya contenido duplicado en páginas con palabras clave y que pertenecen a nuestra arquitectura SEO. Por esta razón, el limitar el contenido duplicado optimizará nuestra web y permitirá que los buscadores la indexen y entiendan mucho mejor.
Una de estas herramientas es www.siteliner.com. Tras introducir el dominio de nuestra página la rastreará buscando el cumplimiento de muchos factores y uno de ellos será el contenido duplicado interno. Este análisis a día de hoy es gratuito.
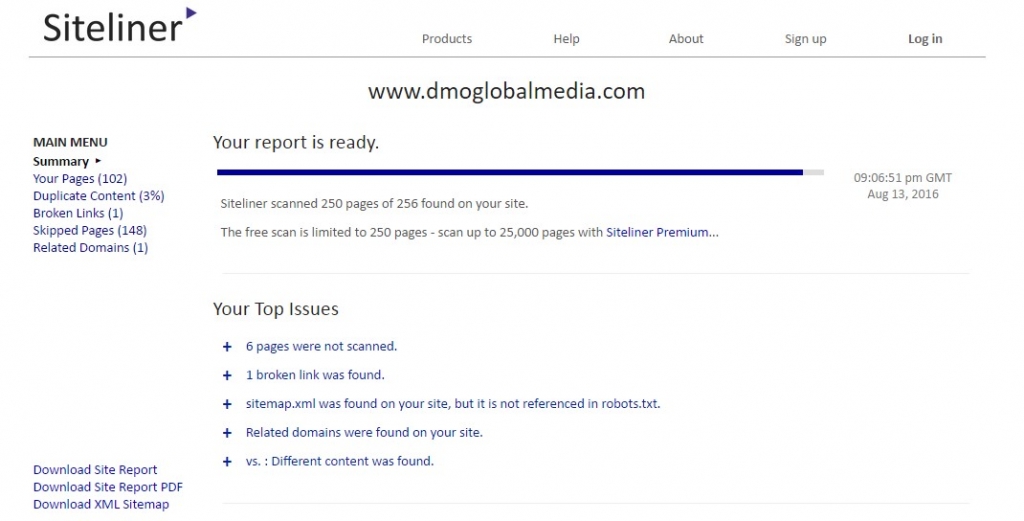
En este ejemplo vemos como tras analizar una web completa nos indica que este dominio tiene muy poco contenido duplicado. Al bajar más en el informe podremos ver que el 3% del contenido de la web está duplicado.
Debemos tener en cuenta que esta herramienta no distingue de menús, cabeceras, pies de páginas y barras laterales, por lo que siempre detectará contenido duplicado.
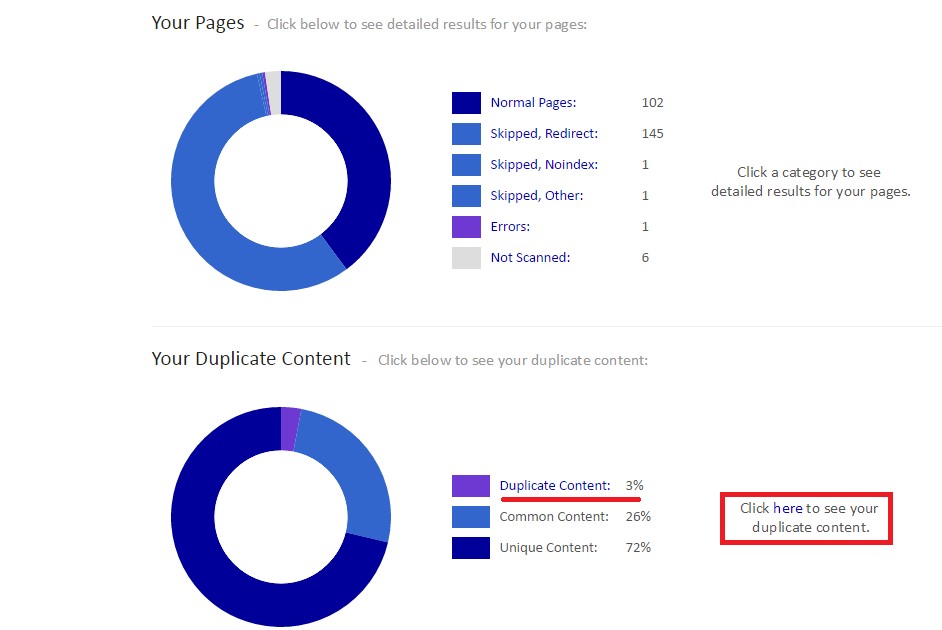
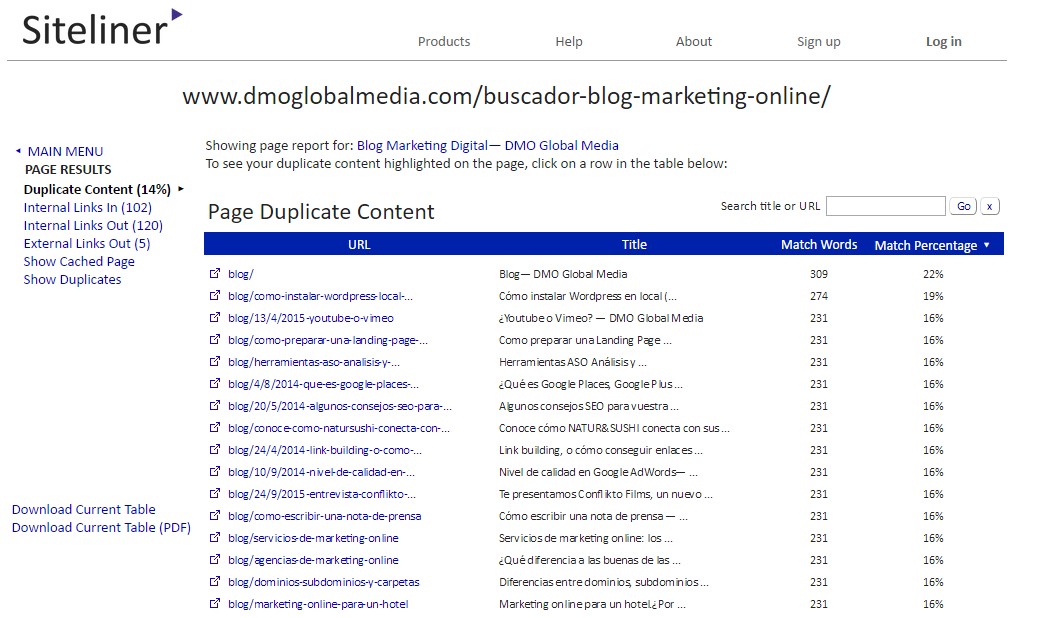
Deberemos entonces pinchar en “Click here to see your duplicate content”, apareciéndonos un largo listado con todas las páginas con contenido duplicado, la cual deberá ser ordenada de mayor a menor por la columna “Match Percenatage”.
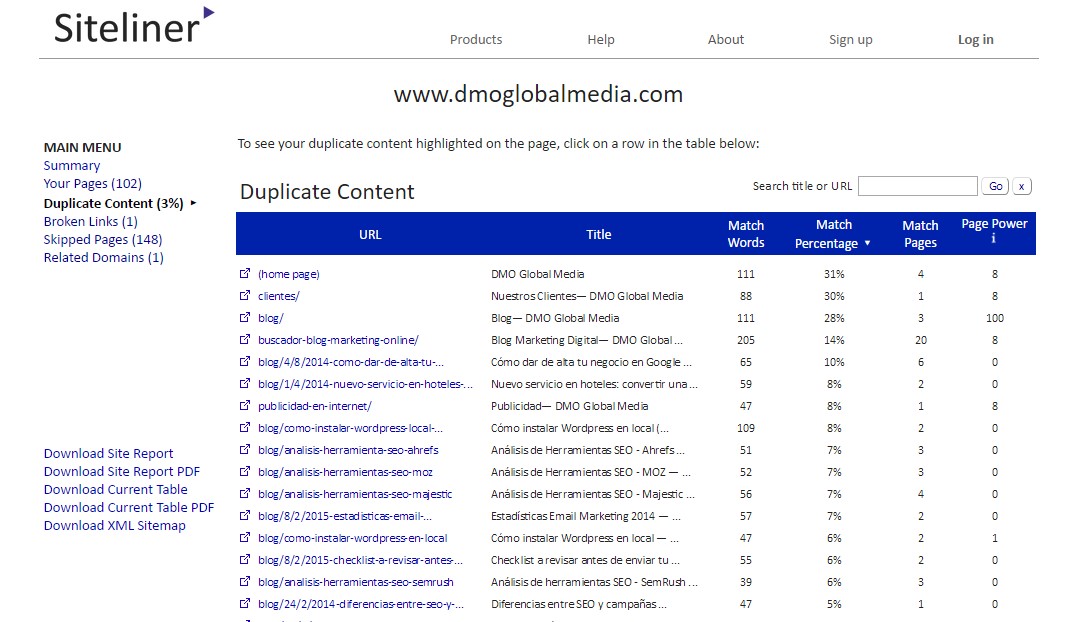
Serán aquellas filas que tengan un porcentaje de contenido duplicado superior al 10-12% las que deberemos analizar. Al pinchar en cada fila nos saldrá la página y todo el texto duplicado estará marcado en rojo. En la columna de la derecha podremos ver como se muestra el contenido duplicado y en las páginas que aparece.
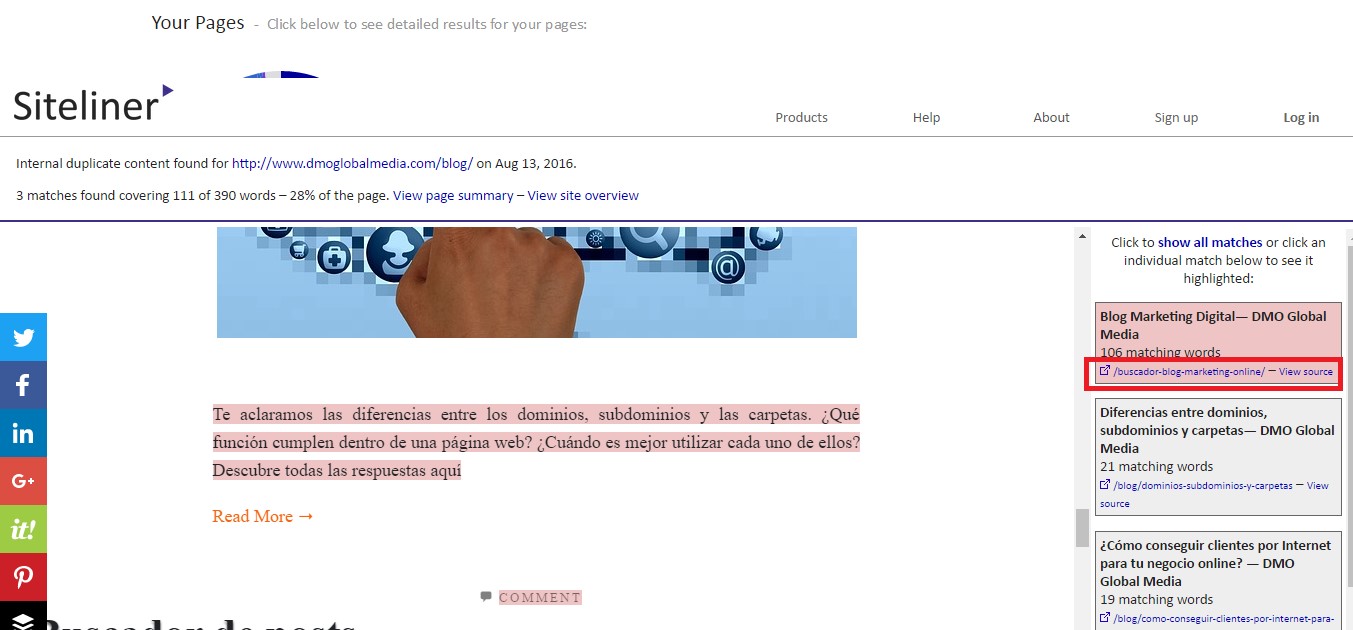
Pinchando en el enlace del contenido duplicado nos aparecerá una nueva tabla con todas las páginas que tienen el contenido marcado en rojo duplicado.
Queremos insistir en que el objetivo de este ejercicio no es reducir a cero el contenido duplicado interno, sino que deberemos optimizar la web para facilitar a los buscadores el análisis de la misma. Para ellos os comentamos a continuación los principales casos de contenido duplicado interno que debemos intentar detectar y evitar:
- Textos con palabras clave.
Si por ejemplo nuestra estrategia está basada en posicionar la palabra clave “hoteles en raja ampat”, claramente deberemos evitar duplicidad en cualquier texto que incluya nuestra palabra clave para que no genere confusión a Google.
- Categorías y etiquetas de nuestra web.
Una estrategia que a veces funciona de posicionamiento es crear categorías con palabras clave de nuestra estrategia permitiendo crear contenido posicionado por esta palabra clave. Por ejemplo, si creamos una categoría “Maquinaria Hostelería” y nuestra estrategia es la de conseguir posicionar por “Maquinaria Hostelería”, cada vez que publiquemos un post y lo categoricemos como “Maquinaria Hostelería”, el contenido de la página www.dominio.com/categoria/maquinaria-hostelería será mayor, alimentando la calidad del posicionamiento de esta palabra clave.
Esta técnica puede funcionar, pero ojo, no debemos posicionar ninguna otra página por este contenido. El problema que tiene esta técnica es que el 98% de la página es contenido duplicado, al estar compuesta por fragmentos de posts clasificados con esta categoría. La forma de solucionarlo es configurar a nuestra web que muestre fragmentos que sean diferentes a los de los posts originales, por ejemplo, configurando una descripción o entrada para el post y otra para mostrar sólo en las páginas de las categorías.
La recomendación general en este caso es no indexar estas páginas y optimizar así el contenido de nuestra web y provocar que Google sólo indexe el contenido único y de calidad. Ahora bien, cada web es diferente y en ciertos casos se podría estudiar la posibilidad de permitir que los buscadores indexen estas páginas.
Aquí hemos hablado sobre el caso de las categorías, pero para las etiquetas podría pasar lo mismo, pero en esta ocasión, debido a la gran variedad de etiquetas que se pueden llegar a crear sí que recomendamos en gran medida no permitir que los buscadores indexen las páginas con el contenido clasificado por etiquetas.
- Utilización de urls iguales, pero con terminaciones diferentes.
Este apartado puede parecer algo simple, pero si las redirecciones internas las hacemos en unas ocasiones apuntando a la url www.dominio.com/pagina-ejemplo y en otras ocasiones apuntando a www.dominio.com/pagina-ejemplo/ para Google podrán llegar a ser dos páginas diferentes, o al menos le generará confusión.
Antes de diseñar una página debe tomarse una decisión, si acabar las urls con / o sin / y llevarla a cabo en toda la web.
- Contenido duplicado por utilización de parámetros en la url.
Antes de continuar deberemos insistir en que el uso de parámetros en las urls no es una buena práctica para hacer un buen diseño SEO. Para google que una url soporte parámetros quiere decir que esa página puede generar infinitas combinaciones de contenido que le va a ser imposible analizar, por lo que no podrá saber todo el contenido que tiene la página. ¿Crees que Google querrá llevar a sus clientes a una web de la que no conoce parte o gran parte de su contenido? Más detalle sobre los parámetros en las urls lo podremos ver en la sección de parámetros en urls.
Uno de los ejemplos más claros de contenido duplicado es la utilización del parámetro de orden. Imaginemos que tenemos una página que devuelve 10 elementos en una tabla y uno de los parámetros de la url es order=desc o order=asc. Para Google esto son dos páginas diferentes y el contenido es el mismo.
Para solucionar este problema deberemos indicarle a Google que no utilice estos parámetros.
- Contenido duplicado por tener la misma web en el dominio dominio.com y en el dominio dominio.com o incluso en la ip.
Esto se vio en el apartado de redirecciones entre dominio. La manera de solucionar este problema es redirigiendo el contenido de un dominio a otro. Si también el contenido se duplica porque se puede acceder por IP, entonces también se deberá redirigir el contenido de la ip al dominio elegido final.
- Se duplica el contenido porque tenemos el dominio seguro (https) y el no seguro (http) sin redirigir el no seguro al seguro, generando duplicidad de contenido.
- Utilización de identificador de sesión.
Antiguamente era costumbre el utilizar el identificador de sesión generado por el servidor web al detectar un nuevo usuario para “arrastrarlo” por las diferentes páginas de una web como parámetro para poder personalizar el contenido de la web. Para esto se utilizaba el parámetro id, por ejemplo, accediendo a la página www.dominio.com/?id=68799898. Como se puede comprobar, el número de valores que puede albergar este parámetro es infinito y para Google generará de nuevo confusión al detectar todo este contenido duplicado. Este problema se soluciona no utilizando identificador de sesión como parámetro.
- html o index.php
Algunas webs pueden albergar mismo contenido para diferentes urls. Por ejemplo, hay webs que si accedes a la página home (www.dominio.com) accedes al mismo contenido que si accedes a la url www.dominio.com/index.html o www.dominio.com/index.php. Debemos evitar a toda costa este tipo de duplicidad. Esto lo podremos hacer no indexando las páginas index.html e index.php en los sitemap.xml y evitando enlaces a estas páginas en nuestra web. Si ya tenemos el problema, entonces deberemos hacer redirecciones 301 de las páginas index.html o index.php a la página donde queremos dejar el único contenido.
- Mismo idioma, pero para diferentes países o regiones.
En el caso en el que tengamos una marca que queremos posicionar en diferentes países y para cada país tenemos nuestro propio dominio y subdominio, aunque el ingés de Canada y el de Australia tenga ciertas diferencias, puede que el contenido de una misma página sea exactamente igual. Para solucionar este problema existe el tag link con el atributo hreflang. Sobre este atributo hablamos más en la sección de multiidioma e internacionalización, pero para esta sección, simplemente basta decir que indicando que hay un contenido similar, pero en otro idioma con estas etiquetas HTML será suficiente.
Si tenemos una página con contenido idéntico en estas dos páginas dominio.com/producto y en dominio.ca/producto introduciendo en la primera página la siguiente etiqueta:
<link rel=”alternate” hreflang=”en-CA” href=”http://dominio.ca/producto” />Y en la segunda:
<link rel=”alternate” hreflang=”en-US” href=”http://dominio.com/producto” />Será suficiente para que Google sepa que debe mostrar una página u otra en base al idioma de su cliente. Para más información leer el artñiculo sobre posicionamiento SEO internacional.
- Páginas de impresión
En algunas ocasiones hemos visto como ciertas páginas de una web poseen una página homónima para poder realizar la impresión, la cual tiene unos estilos diferentes ajustados y preparados para la impresión. Debemos asegurarnos que estás páginas no son indexadas por los buscadores para que no haya contenido duplicado.
- Pdfs idénticos o similares a páginas webs.
En ocasiones, podemos querer que nuestra página HTML tenga el mismo contenido en formato doc o pdf para que nuestros usuarios se lo puedan descargar. En esta ocasión el contenido claramente estará duplicado. Por lo visto, Google no muestra gran preocupación por la duplicidad de este contenido y siempre ha dicho que prevalecerá el contenido HTML sobre el de otros formatos. A nosotros también nos interesa que prime el HTML, pues como podemos ver en la sección donde hablamos sobre trucos de usabilidad, el tener contenido indexado en PDF provoca pérdida de usuarios, los cuales acceden al pdf, se lo bajan y no tienen ni por qué pasar por nuestra página y conocer nuestra marca.
Si tenemos mismo contenido en HTML y otros formatos, es recomendable que estos ficheros salgan del índice de los buscadores sacándolos del sitemap.xml (si lo están), evitando que se rastreen añadiendo el disallow en el robots.txt (no asegura que se elimine del índice) y poniendo en los enlaces que apunten al pdf o el documento a eliminar del índice el atributo nofollow.
<a href="”/fichecros/fichero.pdf”" rel="”nofollow”">Descargar fichero</a>Otra de las herramientas que podemos utilizar para detectar contenido duplicado interno es copyscape, pero en esta ocasión se necesita acceso Premium para poder utilizarla.
Detectar contenido duplicado externo
Si en el caso del contenido duplicado interno, el tener contenido duplicado puede provocar confusión a los buscadores no sabiendo qué páginas posicionar por qué contenido, en el caso del tener contenido duplicado externo (alguna de nuestras páginas ha copiado contenido de otra página de otra web), puede provocar que los buscadores eliminen de su índice nuestras páginas o las releguen a muy malas posiciones en el ranking.
Por esta razón es muy importante que nuestra página nunca plagie contenido. Para detectar contenido externo duplicado recomendamos la herramienta copyscape (www.copyscape.com), la cual, cobra 0,05$ por el análisis de cada página de nuestra web. En el caso en el que nuestra página se vaya a comenzar desde cero, entonces es muy fácil, hay que trasladar la directriz a nuestro equipo editor que no se debe copiar nada de contenido. En el caso en el que ya tengamos la web hecha y estemos haciendo un análisis SEO, si es recomendado utilizar esta herramienta para todas las páginas indexadas en los buscadores. Os sugerimos que previamente a ejecutar esta herramienta se haga un trabajo de optimización del contenido duplicado interno recomendado en el punto anterior para optimizar nuestro tiempo y el coste a la hora de buscar contenido duplicado externo.
Ahora bien, después de haber leído esta sección, probablemente te estarás preguntando, ¿y si quiero citar una frase o un texto de algún otro sitio? ¿Recibiré penalización de Google? Pues bien, puedes ser penalizado por Google y para evitarlo, las buenas prácticas nos dicen que utilicemos el siguiente tag HTML:
<blockquote class="wp-block-quote"><p>texto duplicado</p></blockquote>También podremos indicar a los buscadores que no analicen ni indexen esta página utilizando directivas noindex y nofollow.
También os recomendamos, para poder evitar cualquier tipo de problema, que cada vez que generéis una página utilicéis la herramienta copyscape (esta funcionalidad es gratuita) para comprobar que el contenido de la página no tiene contenido duplicado.
Para comprobar que nuestro contenido no es duplicado, abriremos la herramienta accediendo a www.copyscape.com e introduciremos la url a analizar pinchando a continuación en el botón go.
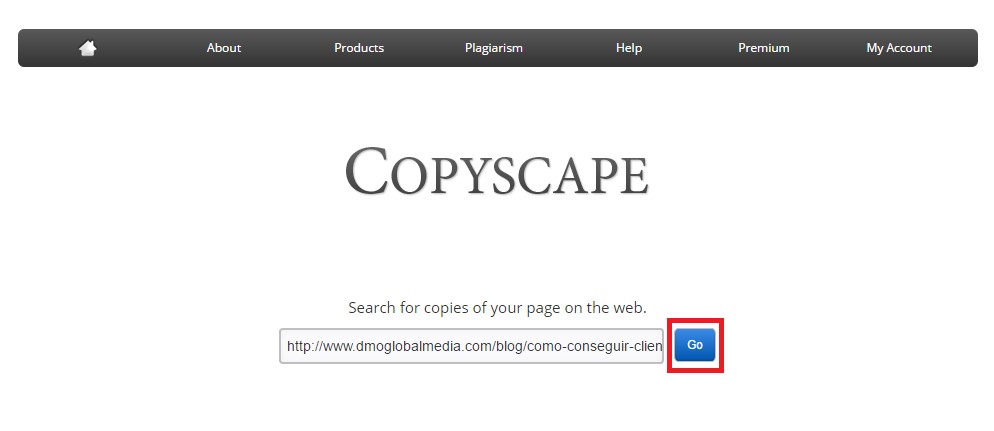
El resultado será el de todas aquellas páginas externas que tengan contenido similar.
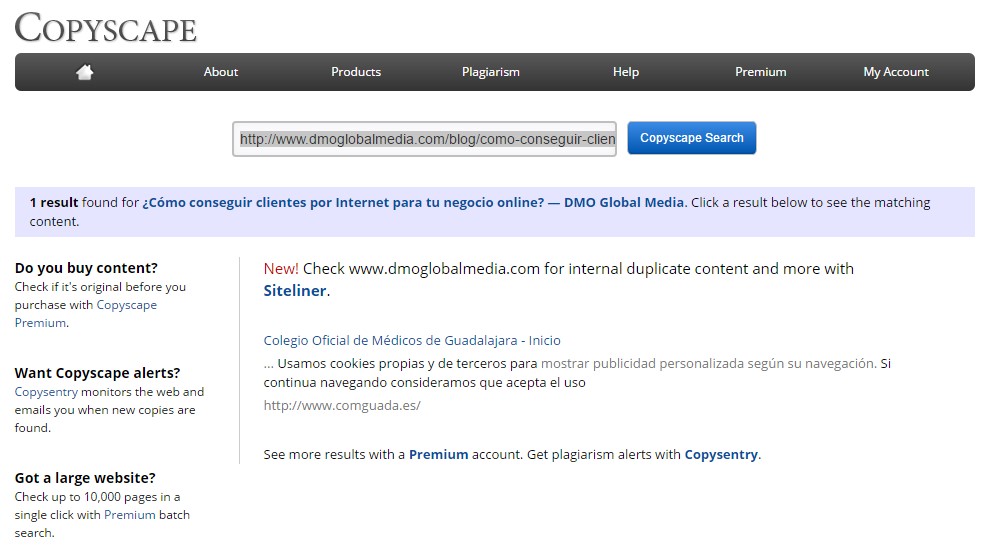
En esta ocasión nos indica la herramienta que nuestra política de cookies está copiada de otra fuente o esta fuente la ha copiado de esta página web.
Tengo que duplicar contenido, ¿Qué hago para no perjudicar mi posicionamiento?
Por alguna razón que pueda existir, la cual no he conocido aún, puede que irremediablemente necesitemos duplicar el contenido de una página web. Pues bien, en este caso podremos utilizar el tag html link con el atributo rel=canonical para indicar a los buscadores que este es contenido duplicado y el original está en la url que indicamos en el tag HTML.
<link rel="canonical" href="http://dominio.com/url-original" />Con la expresión anterior indicamos que la página que tiene en el header la etiqueta de arriba es contenido duplicado y que el contenido original está en http://dominio.com/url-original.
Nota: Sólo puede haber una etiqueta de enlace canónico por página.
Otra opción para solucionar este problema es la de indicarle a los buscadores que no indexen esta página utilizando la etiqueta meta.
<meta name="robots" content="noindex" /> Para aquel caso en el que nuestra página esté duplicando contenido como pequeños párrafos extraídos de otros textos de nuestra web, podremos utilizar el tag HTML blockquote.
<blockquote class="wp-block-quote"><p>texto duplicado</p></blockquote>Nota: es importante conocer esto porque de lo contrario podríamos terminar con alguna penalización de Google que afecte nuestro trabajo. Así evitar terminar preguntándote: ¿Cómo saber si mi web está penalizada por Google?
Principales armas para luchas contra el contenido duplicado interno
Aunque las hemos anteriormente de forma desperdigada, creo que es interesante mostrar una lista resumen de las principales armas o formas que tenemos para evitar problemas de contenido duplicado. Así, cada vez que detectéis un problema de duplicidad podáis ver las principales armas con las que lo podéis solucionar:
- Directrices noindex y nofollow
- Redirecciones 301
- Herramienta de Google Search Console para indicar el funcionamiento de los parámetros de las urls
- Urls canonicas
- atributo hreflang
- blockquote
Como podéis ver, el contenido duplicado en una web es muy nocivo para nuestro posicionamiento. Lo ideal es optimizar el contenido duplicado interno para que haya el menor posible y erradicar totalmente el contenido duplicado externo. ¿Conocéis algún otro tipo de caso y solución de contenido duplicado externo o interno?




Hola, me encanto el post. Pero tengo una duda.
No termine de entender acerca de la parte de categorías y etiquetas, no pude entender casi nada del asunto, ¿Me podrías informar un poco mas simple? ¿O con diferentes palabras?
Gracias de antemano.
Buenas tardes.
Después de leer tu artículo, aún así, no consigo solucionar mi problema.
Estoy tratando de indexar mi web y no se indexa porque, según Google, la URL no se ha seleccionado como canónica.
De hecho, Google ha seleccionado como canónica otra web que no tiene que ver con la mía, y es por eso por lo que no me indexa la web.
¿cómo seleccionar como canónica la url de mi web?
He probado de todo (quitar propiedad del Search Console, volver a verificarla…).
Captura de pantalla:
https://ibb.co/PDhsqsK
¿Qué puede ocurrir?
Gracias.
Saludos.
Hola Fernando, por lo que parece Google ha leído antes que tu página la página que menciona como url canónica. Lo que puedes hacer es hablar con el dueño de esa web y decirle que ponga en su código que la url canónica es la tuya, o bien que elimine el contenido duplicado si lo ha duplicado. Lo que se me hace raro es que por lo visto lo que se ha copiado es la home.
Hola Luna, muchas gracias por tu comentario. Me alegro te haya sido de utilidad este post sobre contenido duplicado.
La pregunta que haces tiene una respuesta muy amplia, y depende del tipo de contenido duplicado que tengas…..
Las diferentes opciones que presentas se utilizan en determinados momentos y bajo especiales circunstancias.
La idea es que obtengas una lista con todo el contenido duplicado y decidas por cada página que hacer.
Lo ideal es que elimines el contenido duplicado y utilices redireccione 301, pero puede que te interese dejar la página por alguna razón. En este caso deberás indicarle a Google con el rel canonical que es contenido copiado.
Piensa que lo ideal es hacerle perder el menor tiempo posible a Google, por lo que si una página está copiada eliminala.
Si es una parte de la pagina, entonces intenta escribirlo de otra forma para que Google deje de ver contenido duplicdo.
También puedes utilizar el robots.txt si quieres evitar que Google rastree esas páginas, no te olvides.
Muchas gracias por comentar!
Javier
Hola buenas tardes,
Me ha encantado tu post, me ha sido realmente util, ,me encuentro con un contenido duplicado de un 40% lo cual lo considero bastante alto, existen URL que tienen el nombre de la URL muy parecida y otras donde el contenido es parecido pero no exactamente igual
Cual seria la mejor de las opciones?
Directrices noindex y nofollow
Redirecciones 301
Herramienta de Google Search Console para indicar el funcionamiento de los parámetros de las urls
Urls canonicas
atributo hreflang
blockquote